При наблюдении за распределением поисковых запросов по страницам входа на сайты, можно заметить один странный факт - некоторые страницы не находятся в поиске по словам, которые на этих страницах размещены. То есть, на странице существует текст с ключевым словом, но это слово почему-то «не видно» поисковой системе.
После проведения более детального анализа были выявлены те слова, которые на страницах присутствуют, но поисковыми системами не учитываются. Проверка показала, что слова эти написаны с ошибкой, однако ошибкой не явной (когда, например, между слов пропущен пробел), а ошибкой, связанной с версткой страницы.
Так, конструкция вида <strong>Оптимизация</strong><strong>сайтов</strong> приводит к тому, что страницу можно найти только по слову «оптимизациясайтов», и нельзя найти по фразе «оптимизация сайтов».
Для сайтов со сложной версткой, страницы которых содержат много блоков, проблема может быть достаточно серьезной. Судя по количеству найденных в поиске результатов по запросам вида «продажаквартир», «продажаавто» и т.д., подобная «склейка» слов является проблемой для большого количества сайтов.
В связи с этим было решено провести эксперимент и определить, какие HTML-теги с какими разделителями приводят к «склеиванию» рядом стоящих слов, а в каких случаях поисковые системы разделяют слова.
Цель эксперимента:
Определить последовательности HTML-разметки, которые затрудняют или делают невозможной правильную индексацию текста документа.
Проблематика:
Текст является ключевой составляющей для возможности поиска той или иной страницы в интернете, а наличие ошибок в тексте существенно затрудняет индексацию. И если с явными ошибками все понятно, и ПС научились их исправлять и учитывать при выдаче, то неявные ошибки, к каковыми и относится «склеивание» могут доставить кучу неприятностей.
«Склеивание» слов может быть связанно с их ошибочным написанием, с пропущенным пробелом между словами или между знаком препинания и следующим за ним словом, а также с ошибкой в разметке страницы. Как видно, примеров «склеенных» слов много:
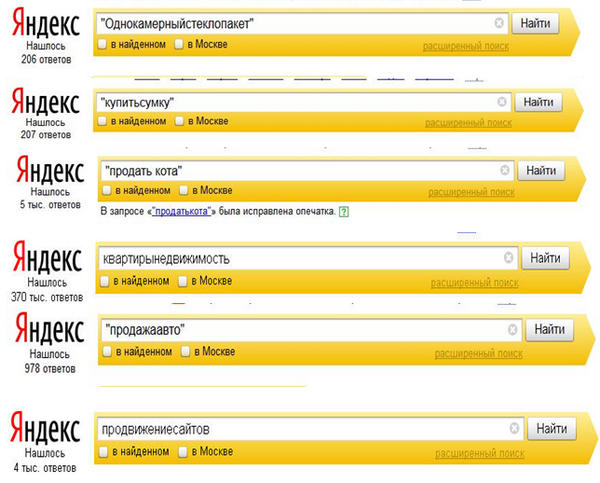
Ошибки подобного типа можно разделить на две группы – естественные (опечатки) и системные (вызванные техническими особенностями разметки текста).
Мы обратили внимание, что одна часть тегов разметки однозначно разделяет слова фразы для поисковой системы, а другая часть не разделяет. Это знание некоторые используют для сокрытия от автоматических систем фильтрации слов-маячков – так называемая обфускация кода.
Какие же именно HTML-теги приводят к склеиванию слов? Логическим дополнением к эксперименту будет проверка последовательностей ( . , ? ! : ; \n \t & nbsp;) с разметкой, которые также приводят к склейке слов.
Эксперимент
Для проведения эксперимента были созданы тестовые страницы.
Фразы:
Были взяты наиболее частотные биграммы из Национального корпуса русского языка.
Теги разметки:
<address>, <blockquote>, <center>, <div>, <h1>, <h2>, <h3>, <h4>, <h5>, <h6>,
<ol>, <p>, <pre>, <table>, <ul>, <article>, <aside>, <footer>, <header>, <mark>, <menu>, <nav>, <section>, <time>, <a>, <abbr>,
<acronym>, <b>, <basefont>, <big>, <br>, <cite>,
<code>, <dfn>, <em>, <font>, <i>, <kbd>, <q>, <s>, <samp>,
<small>, <span>, <strike>, <strong>, <sub>, <sup>, <tt>, <u>, <var>
Знаки разделители:
"!", "?", ",", ".", ":", ";", "\n", "\t", " " <& NBSP>;
Последовательности тегов
<tag>слово1</tag>[разделитель/пропуск пробела]<tag>слово2</tag>
<tag>слово1[разделитель/пропуск пробела]<tag>слово2</tag></tag>
Проверочные запросы
Yandex
- слово1слово2 url:страница
- слово1 слово2 url:страница
- слово1слово2 inurl:страница
- слово1 слово2 inurl:страница
На начальном этапе использовались проверочные запросы без уточнения. Результаты наблюдений по ним были отнесены к не корректны, т.к. поисковые системы показывают результат в случаях частичного совпадения с искомым запросом.
Было принято решение использовать уточняющую формулировку в проверочных запросах к поисковым системам.
Yandex
- "слово1слово2" url:страница
- "слово1 слово2" url:страница
- "слово1слово2" inurl:страница
- "слово1 слово2" inurl:страница
Выбранные для исследования теги относятся к следующим группам:
- Строчные
- Блочные
- HTML5 (понимаем, что блочные и строчные, но рассматриваются они отдельно)
Разделители можно группировать следующим образом:
- Пропущен пробел
- Знаки препинания
- Специальные разделители
Результат проведенного эксперимента:
- Индексация текста поисковыми системами в выделенных группах сходна, за некоторыми исключениями.
- Индексация цепочек текста и тегов (вложенные, последовательные) одинакова.
Блочные элементы:
<address>, <blockquote>, <center>, <div>, <h1>, <h2>, <h3>, <h4>, <h5>, <h6>,
<ol>, <p>, <pre>, <table>, <ul>
Ошибка в разметке текста блочными элементами скрывает от поисковой системы фразу, взятую в кавычки. Нет результатов ни с пропуском пробела, ни со знаками препинания, ни с символами переноса строки, табуляция, неразрывный пробел.
При этом поисковые системы находят каждое отдельное слово фразы. Таким образом, можно сделать вывод о том, что блочные элементы делят слова, разделяя сам текст на блоки (пассажи). Каждое отдельное слово попадает в соседние блоки, поэтому они не находятся по строгим запросам, но видны поисковой машине по обычному запросу без кавычек.
HTML5:
<article>, <aside>, <footer>, <header>, <mark>, <menu>, <nav>, <section>, <time>
Все ошибки в тегах HTML5 для Google делают фразу в кавычках невидимой. Поисковая система не показала результата ни с одним вариантом размещения.
Yandex, в основном, относится к тегам HTML5 также, как и к блочным, за исключением <mark> и <time>
Пропуск пробела:
Yandex находит «слово1слово2», и не находит «слово1[пробел]слово2»
<mark>слово1</mark><mark>слово2</mark>
<mark>слово1<mark>слово2<mark></mark>
<time>слово1</time><time>слово2</time>
<time>слово1<time>слово2</time></time>
Знаки препинания:
Yandex находит «слово1слово2», и при этом находит последовательность «слово1[знак препинания]слово2»
<mark>слово1</mark>[знак препинания]<mark>слово2</mark>
<mark>слово1[знак препинания]<mark>слово2<mark></mark>
<time>слово1</time>[знак препинания]<time>слово2</time>
<time>слово1[знак препинания]<time>слово2</time></time>
Специальные разделители:
Yandex НЕ находит «слово1слово2», и находит «слово1[пробел]слово2» .
<mark>слово1</mark>[разделитель]<mark>слово2</mark>
<mark>слово1[разделитель]<mark>слово2<mark></mark>
<time>слово1</time>[разделитель]<time>слово2</time><time>слово1[разделитель]<time>слово2</time></time>
Строчные элементы:
<a>, <abbr>, <acronym>, <b>, <basefont>, <big>, <br>, <cite>,
<code>, <dfn>, <em>, <font>, <i>, <kbd>, <q>, <s>, <samp>,
<small>, <span>, <strike>, <strong>, <sub>, <sup>, <tt>, <u>, <var>
Наибольшее количество различных вариантов индексации встречается именно на строчных элементах. Строчные элементы чаще всего используются для стилевого оформления текста, и именно они требуют повышенного внимания.
- Специальные разделители – однозначно разделяют слова. Поисковые системы находят «слово1[пробел]слово2» и не находят «слово1слово2».
- Знаки препинания позволяют найти «слово1[пробел]слово2» и последовательность «слово1[знак препинания]слово2».
Стоит сразу отметить, что к тегам <basefont>, <br> Google относится аналогично блочным. В силу особенностей назначения этих тегов, такое отношение можно считать оправданным.
Пропуск пробела:
Yandex:
склеивает слова, находит «слово1слово2» и не находит «слово1[пробел]слово2», за исключением тега BR. Тег BR однозначно делит слова, Yandex находит «слово1[пробел]слово2» и не находит «слово1слово2».
Google:
Ошибки в разметке тегами - <a>, <abbr>, <acronym>, <cite>, <code>, <dfn>, <kbd>, <q>, <samp>, <span>, <sub>, <sup>, <var> – однозначно разделяют слова, Google находит «слово1[пробел]слово2» и не находит «слово1слово2»
Ошибки в разметке тегами - <b>, <big>, <em>, <font>, <i>, <s>, <small>, <strike>, <strong>, <tt>, <u> – приводят к склейке слов, Google находит «слово1слово2» и не находит «слово1[пробел]слово2».
Вывод:
Блочные элементы:
Эксперимент показал, что проблемы склейки слов на блочных элементах не существует, т.к. страницы находятся по нестрогим запросам.
HTML 5:
Необходимо использовать разделители для тегов <mark> и <time>, для предотвращения склейки слов. После знаков препинания в обязательном порядке должен быть пробел.
Строчные элементы:
Необходимо использовать разделители для предотвращения склейки слов. Неразрывный пробел для Yandex не является однозначным разделителем. После знаков препинания должен быть пробел.
Разделители:
Пробел, перенос строки, табуляция,
Примечание:
После знаков препинания обязательно должен быть пробел. Большую значимость имеет пробел после точки, разделяющей предложения, если он пропущен, то для поисковой системы в пассаж войдут два предложения как одно.
Ошибка в HTML коде может быть ложкой дегтя в бочке меда.